Yahoo Pipes at VendAsta
We finished off a short 1 week development sprint last Friday (sometime in Sep/Nov 2008) which culminated in the current live version of the VendAsta website. Despite such a short dev-cycle, I feel we were able to accomplish most of our research goals.
One of the tools we used that I didn’t have much experience with prior was Yahoo Pipes. We had somewhat of a unique problem to solve; we wanted to be able to draw from a variety of Feed sources that would filter through to different sections of the site. Before I dove into using Pipes my gut feeling was just to use some sort of feed parsing library in Python that was compatible with AppEngine.
One of the requirements for implementing the feed sources was that it be very easy to update should a feed need to be changed. If we stuck with the Python library implementation and statically coded some feed sources, changes would take significantly more overhead to implement.
We started investigating Pipes as a platform to aggregate all of the content we wanted to re-publish and were impressed by what we found. It turns out that the Pipes interface is much better at providing an easy-to-update set of feed sources for non-programmers. If you haven’t looked at the Pipes interface I highly recommend you do so.
I think Pipes offers so much advanced filtering and splicing functionality in a really tight package, so I’ll attempt to break down some of the modules we used specifically for the VendAsta website.
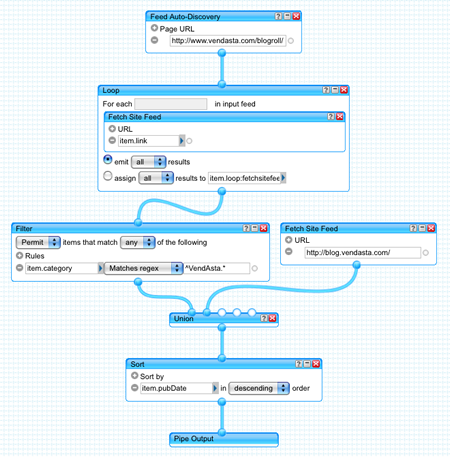
The image above is a shot of the Pipes interface, and more specifically the Pipe that we use to aggregate all of the feed-based content on the VendAsta website. I should clarify, by feed-based content I’m referring to all of the official employee, product, and corporate blogs. Yes you read that right, employee blog posts (when tagged appropriately) end up on our corporate website.
But let’s set aside the trust/ethical issues related to that and focus on the technology we’re using. There are a few components to the root pipe we use to collect all this content, and the Pipes documentation isn’t always entirely clear on the best way to use things, so I will attempt to decompose it and discuss each module in detail.
Feed Auto-Discovery

We have a URL mounted on VendAsta.com that provides only 1 function: spitting out a list of link tags in the following format:
<link rel="alternate" type="application/rss+xml" title="Dave Mosher" href="https://www.davemo.com">
Internally, we store a list of all employees with some meta information like blogURL, linkedinURL etc. This url is what we provide to the auto-discovery module so it can do it’s magic and go out to all of the rss+xml links and gather a list of feeds from the blogs.
Here’s a sample of the output you get from this URL in the Pipes debug console.
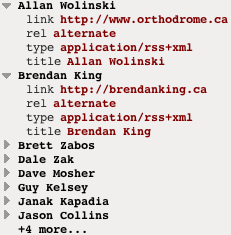
Once we have this list of blogs and the links to them, we can pass the output from the auto-discovery module on to the Loop + Fetch Site Feed modules.
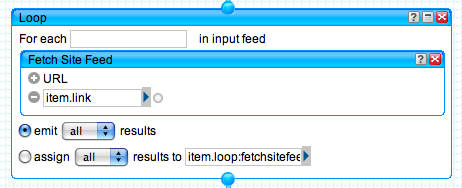
Loop + Fetch Site Feed
The loop module is pretty self explanatory, you use it when you want to iterate over a group of results and operate on them somehow. It’s kind of similar to providing an AJAX onSuccess callback; you send out a request for the content (the iteration) and you define a callback by dragging a supporting pipes function into the available box to process each item. In our case, we’re using the Fetch Site Feed module from the toolbox to snag a feed from each site in our blogroll.
We configure the module to emit all results to our next module, the Filter, which does most of the magic in determining which content ends up on the corporate website.
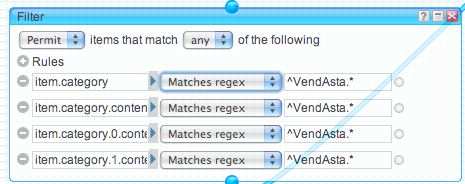
Filter
The filter module works really well for grabbing a set of elements based on a certain set of criteria; in our case we use the Regexp option to explicitly allow any content with the tag/category VendAsta.
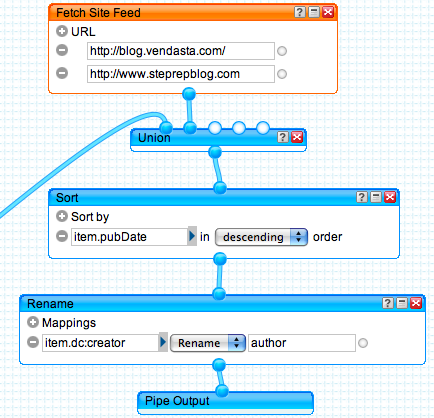
Union, Sort, Rename + Pipe Output
The final layer of our pipe involves combining results from some other static sources independent of filters (VendAsta blog and the StepRep blog), sorting them based on the date published descending, renaming a specific RSS feed field item.dc:creator to author to fix a problem in the feed reading library we’re using server side feedparser.py and finally the output of all these operations: Pipe Output module.
All these modules are really easy to string together with the Pipes interface and are clickable at any point during the creation which will toggle the debug output to stop at the currently selected module. This is very useful for seeing what the modules you are using do at each step of the process.
Pipes as abstract components ties it all together
So now that we have a completed Pipes module, we can do a number of things with it. We can get the output in RSS or JSON format, define a custom url for the pipe, and even give it a name and make it public so other people can use it in their mashups. However, the coolest feature IMHO is that you can use any created pipes module as an abstracted pipes component on it’s own which can be part of another pipes component that you can then perform further operations on.
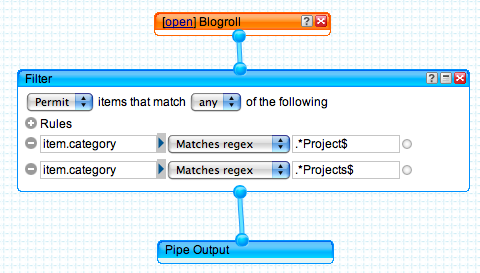
We chose to separate a few of the layers in our feed hierarchy this way for simplicity sake and to keep it loosely coupled if we wanted to make changes to what feeds appear on certain pages. Here’s an example of our previous Blogroll pipe being used as input for further filtering and display on 1 section of the VendAsta website: the Projects page.